Balancing uneven team games - An attempt at quantifying the advantage of the larger team
The issue
When balancing Zero-K team games with an odd number of players, the current balancer tries to find two teams with the same average member rating, without taking team size into account (for example, it thinks that a team of a 2500 Elo player and a 1500 Elo player vs a single 2000 Elo player is 50%). I tried find out how much of an advantage the larger team has, relative to the win rate predicted by WHR. The results indicate that the larger team does have a moderate advantage depending on team sizes and the exact model. Disclaimer: I’m using some of these tools for the first time.
These findings, if correct, could be used to:
Balance uneven team games more accurately.
When updating the ratings of the participants after the game, account for the team size effect. Everything else being equal, winning as a member of the small team is more surprising than winning as a member of the large team.
The following plots show the advantage of the larger team in terms of extra Elo equivalent (see below for the difference between the two models shown. In short, the “jointly fitted” model corresponds to doing both 1. and 2. above, whereas the “Ratings fixed” model takes the unmodified WHR ratings as given and only tries to improve the predictions relative to that.)
The plots represent Bayesian posterior probability densities; the probability that the value is in a given range is proportional to the shaded area over that range. The little circles are the means.
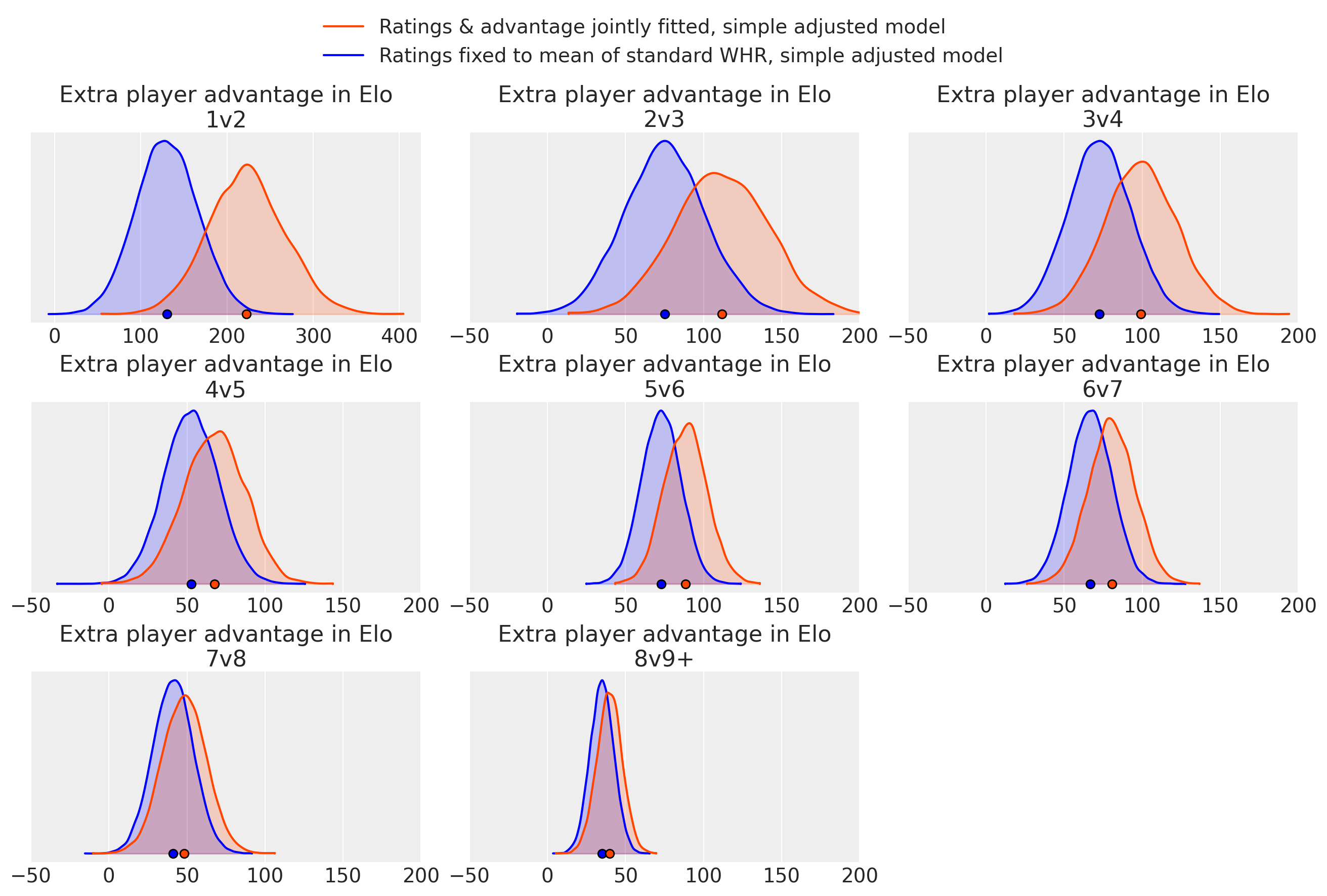
(Different x-axis scale for 1v2.)
We see that there’s strong evidence that the advantage size is positive, but it is kind of disappointingly small.
Note though that these advantages are applied after the usual averaging of team members, so for example for 3v4, an advantage of 100 means that a game with Elos [1300, 1000, 1000] vs [1000, 1000, 1000, 1000] would be fair (50%).
I don’t have a theory yet on why the effect is so much larger for the joint model at some sizes.
Data
Thanks to @malric for providing the data on Zero-K Local Analysis. I initially tried to include all casual-rated games, but then decided to use only games tagged is_autohost_teams and extend the time horizon instead (was reaching the limits of what my hardware can handle in reasonable time), so some of the following filters are probably redundant. I dropped games that:
- were not tagged as teams autohost games
- were noelo
- were FFA (either tagged so, or having team_ids different from 1 and 2)
- had chickens or bots or game mods
- were shorter than 20 seconds
- had no winners (exit?), or no losers somehow
- had a player count difference of more than 1 (should be impossible on autohost)
- were on a “special” map other than Dockside v2, which I heard actually isn’t special.
The filtered dataset included 22150 games and 73858 PlayerDays from 2019 to May 2023, of which 7231 games were uneven-sized (a “PlayerDay” is a day, player pair on which that player played; WHR assigns a rating estimate to every PlayerDay). I actually downloaded the data back to 2017, but for some reason none of the 2017 or 2018 games passed the filter (further research is needed).
I did not have access to the actual player rating histories, so “unmodified WHR” (in the previous section) means the ratings I inferred using the standard WHR model, using only this dataset.
Breakdown of uneven games in the dataset:
| Rating of best player of small team → | < 1800 Elo | [1800; 2200] | > 2200 Elo | |||
|---|---|---|---|---|---|---|
| ↓ winner ↓ | ↓ winner ↓ | ↓ winner ↓ | ||||
| Large | Small | Large | Small | Large | Small | |
| Size | ||||||
| 1v2 | 87 | 28 | 23 | 14 | 5 | 3 |
| 2v3 | 82 | 31 | 52 | 39 | 17 | 16 |
| 3v4 | 89 | 34 | 97 | 69 | 39 | 36 |
| 4v5 | 50 | 23 | 108 | 79 | 115 | 94 |
| 5v6 | 38 | 12 | 179 | 100 | 318 | 234 |
| 6v7 | 15 | 5 | 134 | 94 | 278 | 177 |
| 7v8 | 17 | 9 | 127 | 81 | 307 | 253 |
| 8v9+ | 18 | 14 | 298 | 216 | 1626 | 1451 |
Models
If not already familiar with it, you might want to look at Section 5.2 and 5.3 for the standard (unadjusted) WHR model.
Simple adjusted model
Since the rating averaging with no regard to team size seems wrong, I extended the model by introducing a new parameter which I called epad (extra player advantage), such that if team 1 has one more player than team 2, and if \(r := \text{team 1 natural rating} - \text{team 2 natural rating}\): \[P(\text{team 1 wins} | r) = \text{sigmoid}(r + \textbf{epad}) \equiv \frac{1}{1+\exp(-(r + \textbf{epad}))}\] so the team with one more player is simply treated as if it had epad more rating than it actually has. Unadjusted WHR is the special case when epad = 0.
I expected the advantage size to be different for 1v2, 2v3 etc, so epad is actually an array of parameters, one for each uneven teams size (as mentioned, games with a player count difference > 1 were dropped). Since I didn’t expect much of an effect for large teams, I made 8v9 and higher all share a single parameter epad["8v9+"], with an additional assumption that the effect decreases linearly with the size of the smaller team 1.
I used a weakly informative prior for each epad: \[\text{epad} \sim \text{Normal}(\text{mean} = 0, \text{sdev} = 1000 \text{ Elo})\] which represents a belief like “I have no idea if the larger team has an advantage or a disadvantage, but the effect is probably less than 2000 Elo”. (That’s suppsosed to be a somewhat “objective” prior; my actual personal prior is that the effect is positive2. While it’s true that the larger team has no material advantage (other than more starting position choices), APM matters.)
Best Player of Smaller Team - dependent model
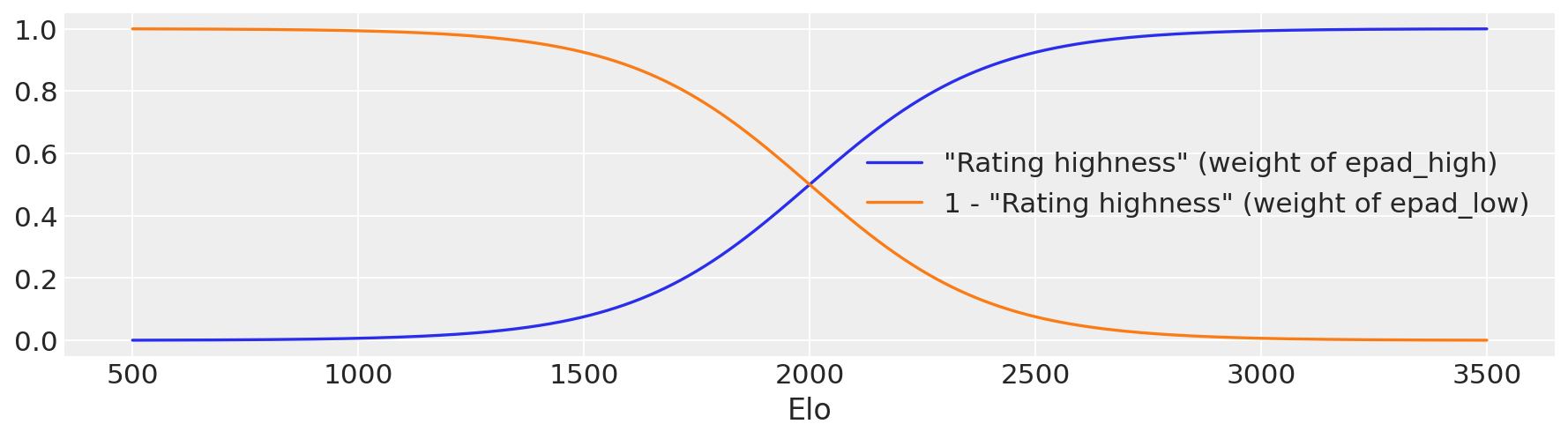
@Sprung plausibly suggested to discriminate by the rating of the Best Player of the Smaller Team (BPST), because they are the one with the double comm. In this second model, epad is a 2d array indexed by both team sizes and rating class, for which I used just “high rating” and “low rating” (I think the data would get too thin with more). I then used a smoothened version of if BPST_Elo < 2000 then epad_low else epad_high as follows. Let b be the Elo of the BPST, then define the “Rating highness” as:
The calculation of the “best” player rating actually uses a smooth approximation to
max, to keep the model differentiable.\[ \text{rh}(b) := \text{sigmoid}\left(\frac{b - 2000}{200}\right) \] \[ P(\text{team 1 wins } | r, b) = \text{sigmoid}\left( r + \text{rh}(b) \cdot \text{epad}_\text{high} + (1 - \text{rh}(b)) \cdot \text{epad}_\text{low} \right) \] The BPST model uses the same prior for each epad as the simple model.
Results for the joint models:
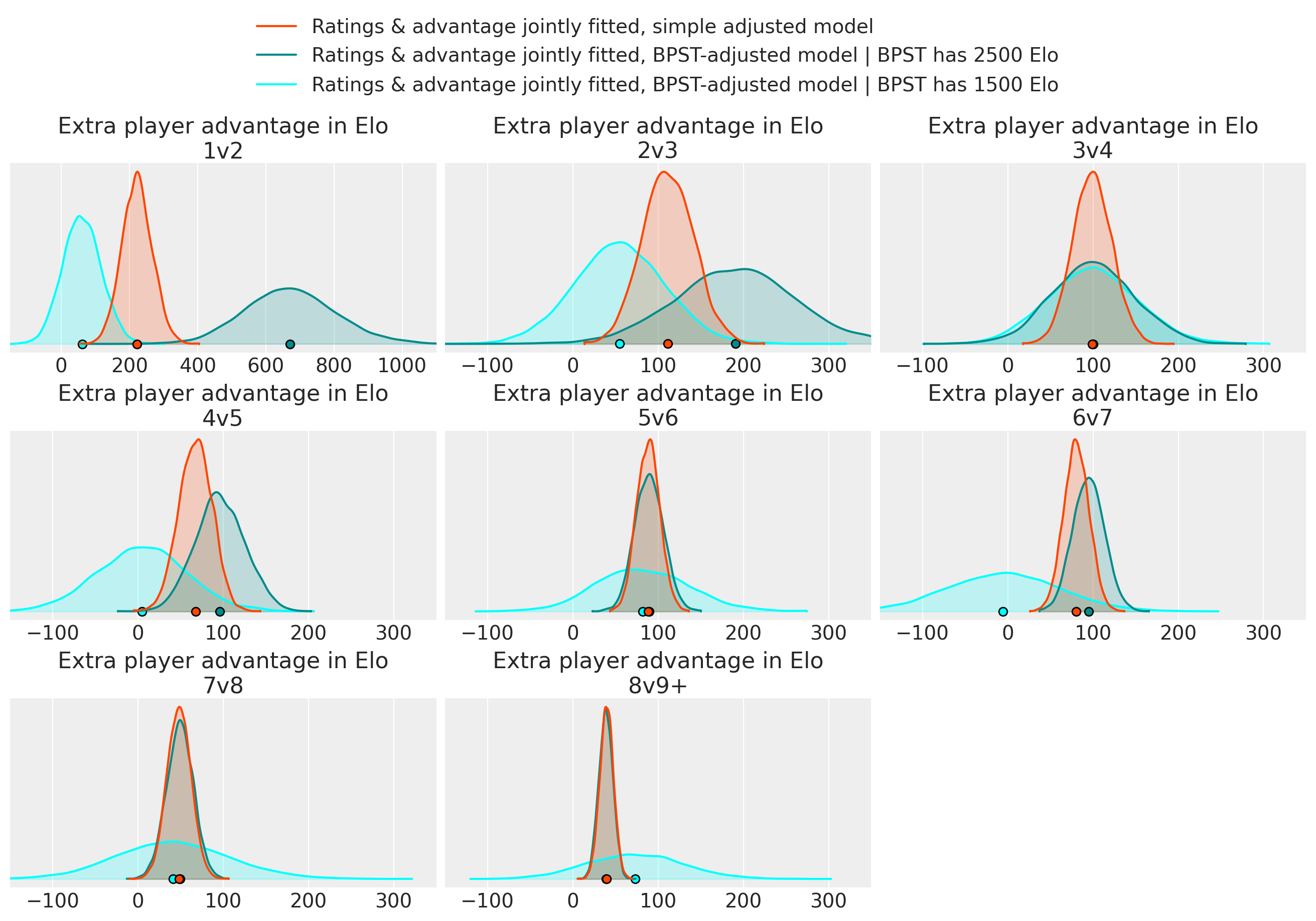
Looking at the game count table, the large uncertainty for the 2500 Elo player in 1v2 and 2v3, and for the 1500 Elo player in 6v7 and bigger are probably due to insufficient sample size. Naturally, the larger the team, the higher-rated its best player tends to be.
In 3v4, and 5v6, the means of all three conditions are oddly close together.
For most of the other sizes, the effect is susprisingly larger if the BPST is high-rated. This means that, say, [2500, 2100] vs [2700, 2100, 2100] (both averages = 2300) is supposedly more in favor of the large team than a similar game shifted down 1000 Elo ([1500, 1100] vs [1700, 1100, 1100]) is. I don’t have an explanation for any of this.
Results for the fixed-rating models:
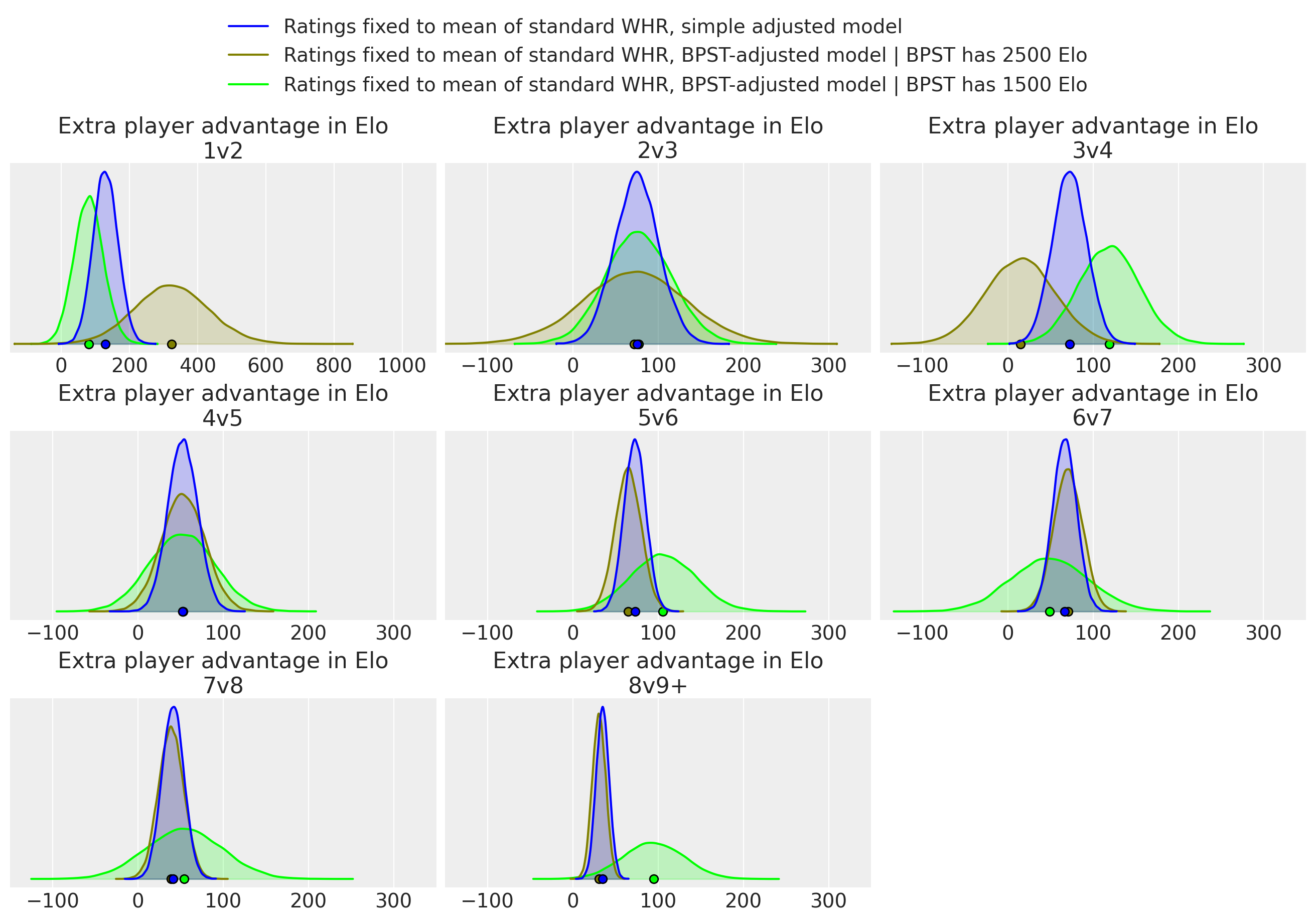
Again a bit weird.
Joint models vs fixed-ratings models
I tried each of the models with two different approaches:
- Joint models
-
Simultaneously infer both
epadand the ratings of the players; both are parameters in the same model. - Fixed-rating models
-
Infer the ratings using the unadjusted model. Take either the posterior mean or the MAP player ratings and use these as fixed ratings in a second model whose only parameters are the
epads.
One could argue that the joint models are the more relevant ones if we want to use the epad both for balancing and for determining ratings, and the fixed models are more relevant if we want to use epad only for balancing. In the former case, assuming epad is found to be positive, players on the smaller team will gain more / lose less Elo on win / loss than they otherwise would.
In any case, the advantage of the fixed models is much faster development iteration; the sampling of the joint models took about 150 minutes each and the resulting traces are 4 GB each.
Concerning the fixed models, the difference between fixing to mean or MAP was minimal (but the MAP does not require sampling and takes just seconds to compute; the full posterior over which the mean is taken takes hours as mentioned):
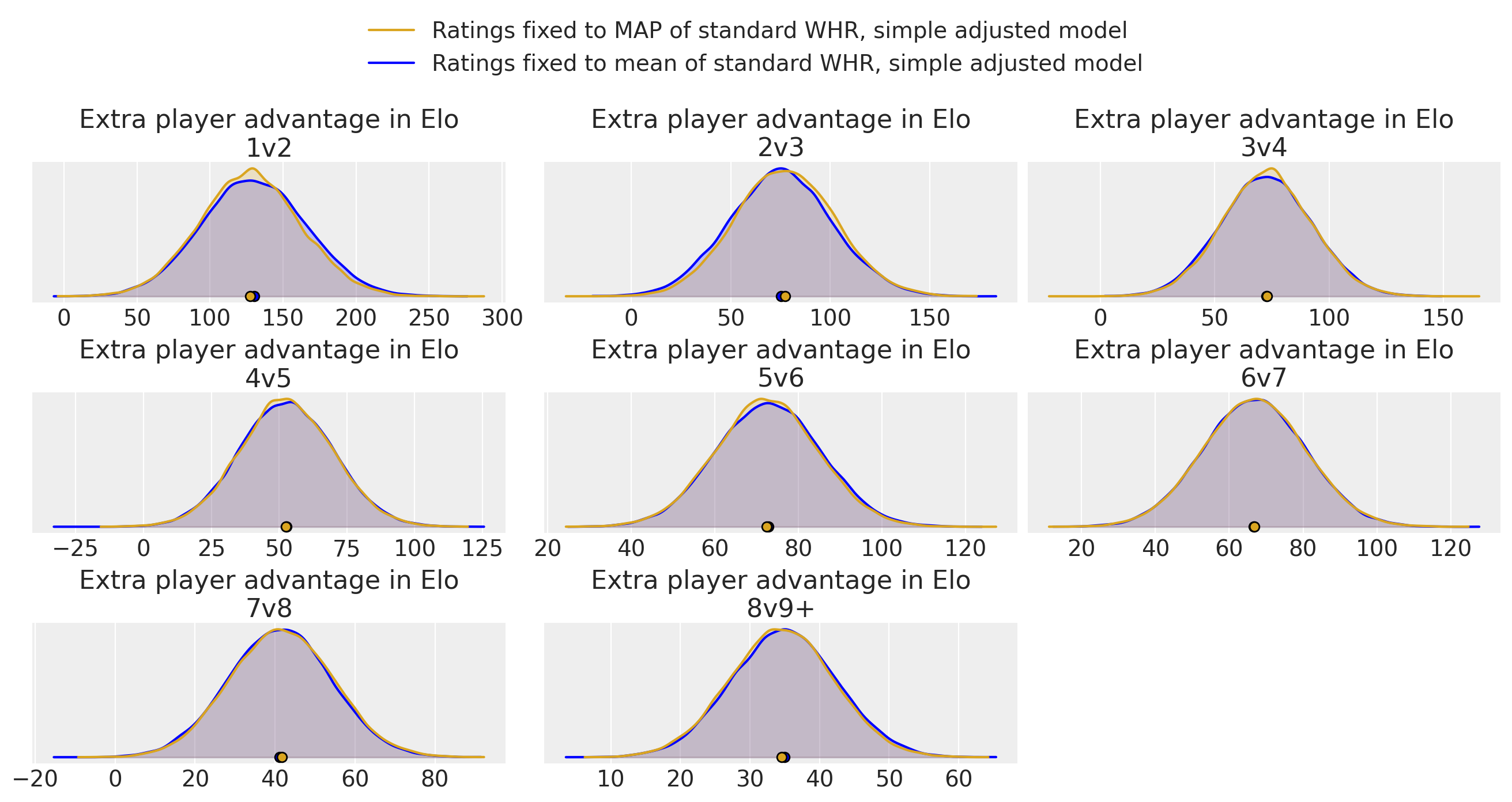
Model comparison
To estimate the out-of-sample predictive performance of the different models, I used something called PSIS-LOO, which is some very clever method for estimating the Leave-One-Out cross-validation performance (i.e. withholding one datapoint, training the model on all the others, then trying to predict the withheld point) for all the datapoints (games) without actually refitting the model N times.
Joint models
| rank | elpd_loo | p_loo | elpd_diff | weight | se | dse | warning | scale | |
|---|---|---|---|---|---|---|---|---|---|
| Ratings & advantage jointly fitted, BPST-adjusted model | 0 | -14662.093146 | 2116.534525 | 0.000000 | 0.673899 | 48.276185 | 0.000000 | True | log |
| Ratings & advantage jointly fitted, simple adjusted model | 1 | -14667.054129 | 2118.937944 | 4.960982 | 0.175391 | 48.293260 | 6.328338 | True | log |
| Ratings & advantage jointly fitted, unadjusted WHR model | 2 | -14739.315606 | 2115.120891 | 77.222460 | 0.150711 | 46.646162 | 15.958799 | True | log |
The meaning of these columns is documented here, but the main point is also expressed in this chart:
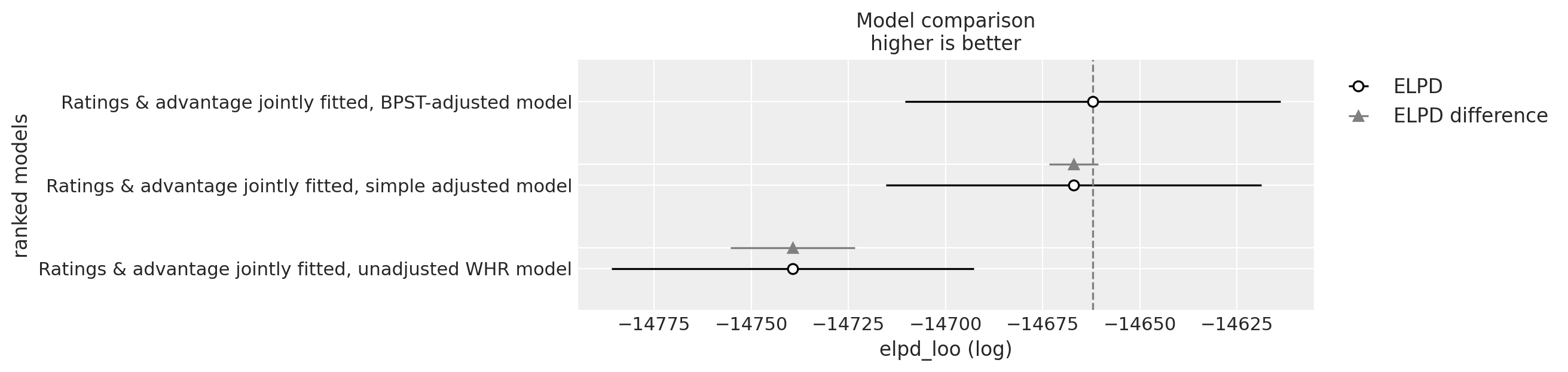
The BPST-adjusted model scores very slightly higher than the simple adjusted model, but both are clearly better than the unadjusted model.
Fixed-rating models
The unadjusted fixed-rating models would have 0 parameters, which the library didn’t like, so I kept the epad parameters but forced its value to be tiny (+- 1 Elo) for the “unadjusted”.
| rank | elpd_loo | p_loo | elpd_diff | weight | se | dse | warning | scale | |
|---|---|---|---|---|---|---|---|---|---|
| Ratings fixed to mean of standard WHR, simple adjusted model | 0 | -4248.331918 | 7.012583 | 0.000000 | 0.734426 | 21.993787 | 0.000000 | False | log |
| Ratings fixed to mean of standard WHR, BPST-adjusted model | 1 | -4250.847614 | 14.378877 | 2.515697 | 0.265574 | 22.187316 | 3.323622 | False | log |
| Ratings fixed to MAP of standard WHR, simple adjusted model | 2 | -4300.795784 | 6.941516 | 52.463866 | 0.000000 | 20.441711 | 2.327563 | False | log |
| Ratings fixed to MAP of standard WHR, BPST-adjusted model | 3 | -4303.209430 | 14.301572 | 54.877512 | 0.000000 | 20.816522 | 4.089969 | False | log |
| Ratings fixed to mean of standard WHR, unadjusted WHR model | 4 | -4308.140811 | 0.011841 | 59.808893 | 0.000000 | 19.694596 | 10.781529 | False | log |
| Ratings fixed to MAP of standard WHR, unadjusted WHR model | 5 | -4362.149017 | 0.012061 | 113.817100 | 0.000000 | 17.712600 | 10.859103 | False | log |
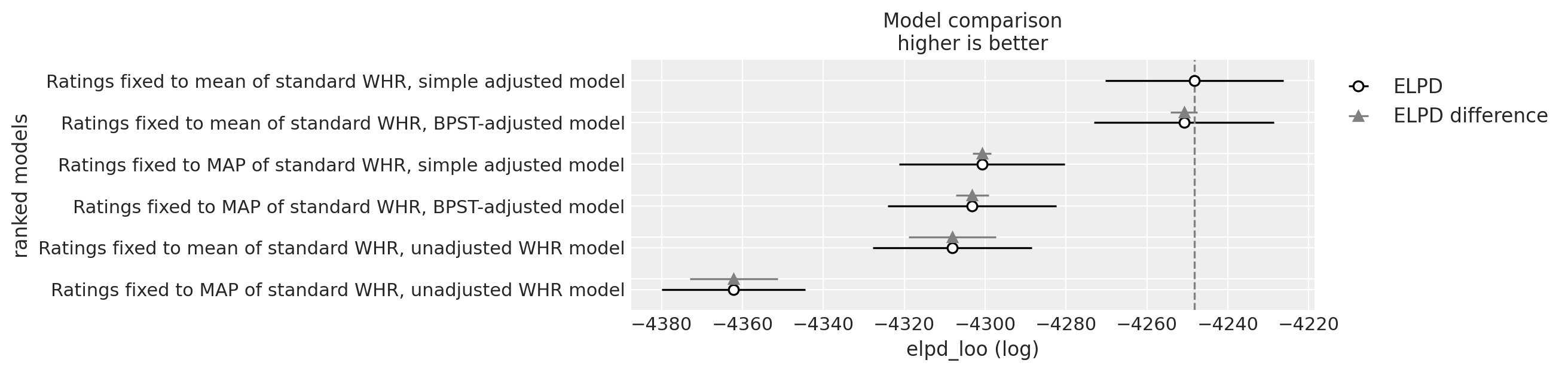
Similar situation, except this time the simple model is slightly ahead. Also, the mean ratings appear to be more predictive than MAP ratings, idk.
The scores of the joint models and the fixed-rating models are uncomparable because the former try to predict all games in the dataset while the latter only look at the uneven-sized games.
Due to the somewhat erratic results with the BPST models (pointing to possible implementation error) and the similar PSIS-LOO scores, I went with the simple models as the “main result”.
Implementation
The models were implemented using the Python library PyMC and the results analyzed using ArviZ. Samples from the posterior were taken using the NUTS sampler (No U-Turn Sampler, a type of Hamiltonian Monte Carlo sampler, where in my very basic understanding, you reinterpret your posterior density function as a physical potential and let a thermal particle bounce around in it.)
The parameters of the implemented model are technically not the ratings, but the increments of the ratings from day to day, in addition to the first-day rating (rating increments are much less correlated than ratings; making the ratings be parameters directly caused incredibly slow sampling).
Summing up the increments to get ratings was tough to optimize because different players have different numbers of days played, but vectorized functions such as cumsum expect to sum equally many numbers in each batch. Tried a bunch of things, but in the end went with a sparse matrix (containing only 0s and 1s) to turn the increments into ratings.
I took 8000 samples for each of the joint models and 32k for the fixed-rating ones:
| model | chains | draws_per_chain | tuning_steps_per_chain | sampling_time | |
|---|---|---|---|---|---|
| 0 | Ratings & advantage jointly fitted, unadjusted... | 4 | 2000 | 1000 | 9148.117072 |
| 1 | Ratings & advantage jointly fitted, simple adj... | 4 | 2000 | 1000 | 9579.752359 |
| 2 | Ratings & advantage jointly fitted, BPST-adjus... | 4 | 2000 | 1000 | 10170.415352 |
| 3 | Ratings fixed to mean of standard WHR, unadjus... | 16 | 2000 | 1000 | 15.865014 |
| 4 | Ratings fixed to mean of standard WHR, simple ... | 16 | 2000 | 1000 | 14.282327 |
| 5 | Ratings fixed to mean of standard WHR, BPST-ad... | 16 | 2000 | 1000 | 25.338659 |
| 6 | Ratings fixed to MAP of standard WHR, unadjust... | 16 | 2000 | 1000 | 16.095270 |
| 7 | Ratings fixed to MAP of standard WHR, simple a... | 16 | 2000 | 1000 | 14.339227 |
| 8 | Ratings fixed to MAP of standard WHR, BPST-adj... | 16 | 2000 | 1000 | 26.411861 |
Background
Bayes
WHR is a Bayesian model, as are the extensions of it in this post. Bayesianism interprets probabilities as representing a state of knowledge or as quantification of a personal belief.. So you can say something like “I think there’s a 20% probability that Krow will be buffed in ZK 1.11.7” even though this is not a repeatable process such as throwing dice, in which case “20%” would represent the long-run average frequency.
In Bayesian inference, we are interested in the values of some unknown parameters (in WHR: The unobservable true rating of each player for each day, and here also the size of the extra player advantage) and start by formulating our belief (before having seen the data) about what the values of the parameters could possibly be; this probability distribution is called the prior (see below for WHR’s prior). We also need to specify a likelihood function, which states the probability of making some specific observation (here: game outcome) if the unknown parameters had some particular value.
Given the prior, the likelihood, and the data/evidence, we can use Bayes’ theorem to “update” our belief about what the most likely values of the parameters are; the updated probability distribution is called the posterior.
The posterior is a probability distribution, but only a single rating value is shown in ZK; AFAIK, this is the value with the highest posterior probability density (also known as the MAP, maximum a posteriori).
WHR’s likelihood function
For WHR, the likelihood function is taken to be:
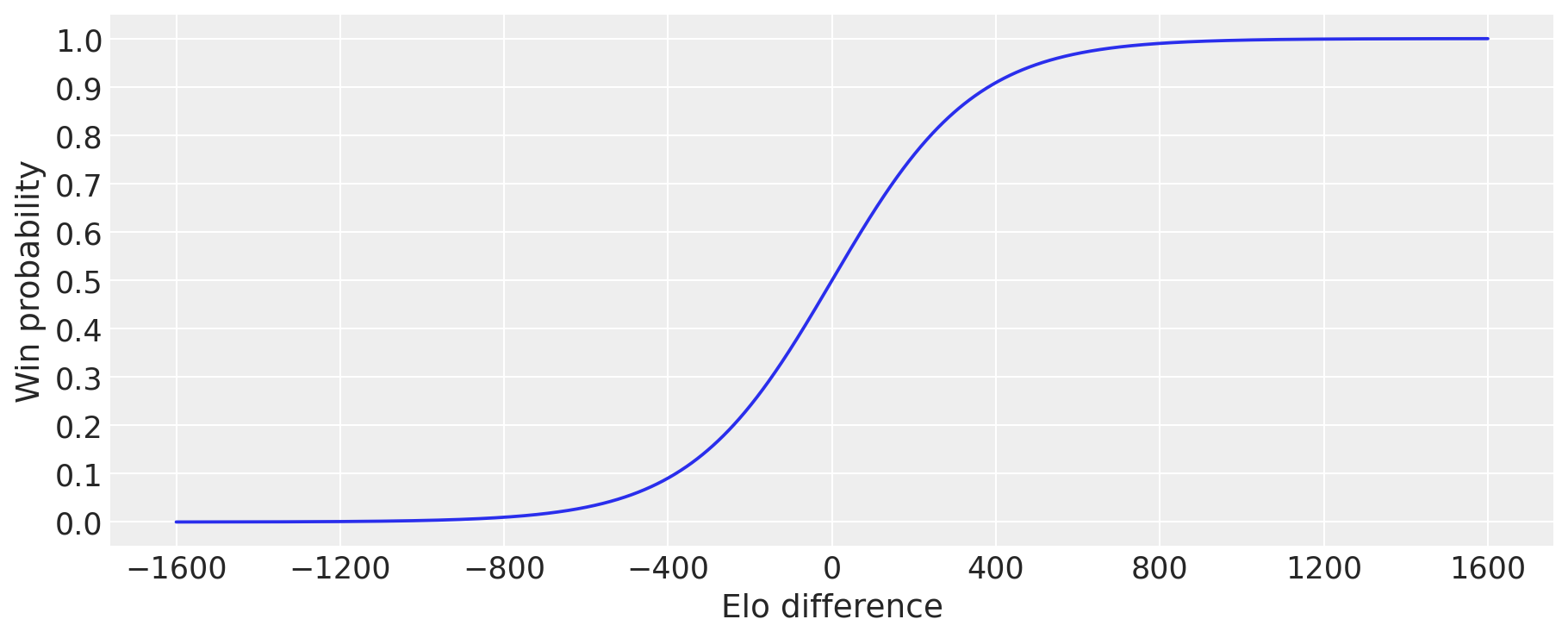
\[\text{Let } R := \text{team 1 Elo} - \text{team 2 Elo, then}\] \[P(\text{team 1 wins} | R) = \frac{1}{1 + 10^\frac{-R}{400}}\]
Of course, the win chance converges to 1 as \(R \to +\infty\), to 0 as \(R \to -\infty\), and is 0.5 if \(R=0\).
It is mathematically convenient to measure the ratings on a scale called “natural rating”3 instead of Elo, where \[\text{1 natural rating} = \frac{400}{\ln(10)}\text{ Elo} \approx 174 \text{ Elo}\]
Then the likelihood is just the standard logistic aka sigmoid function:
\[\text{Let } r := \text{team 1 natural rating} - \text{team 2 natural rating, then}\] \[P(\text{team 1 wins} | r) = \frac{1}{1 + \exp(-r)} =: \operatorname{sigmoid}(r)\]
Team ratings are averaged:
\[\text{Team 1 rating} = \text{average of the ratings of the players on team 1}\] \[\text{Team 2 rating} = \text{average of the ratings of the players on team 2}\]
WHR’s prior
First day rating
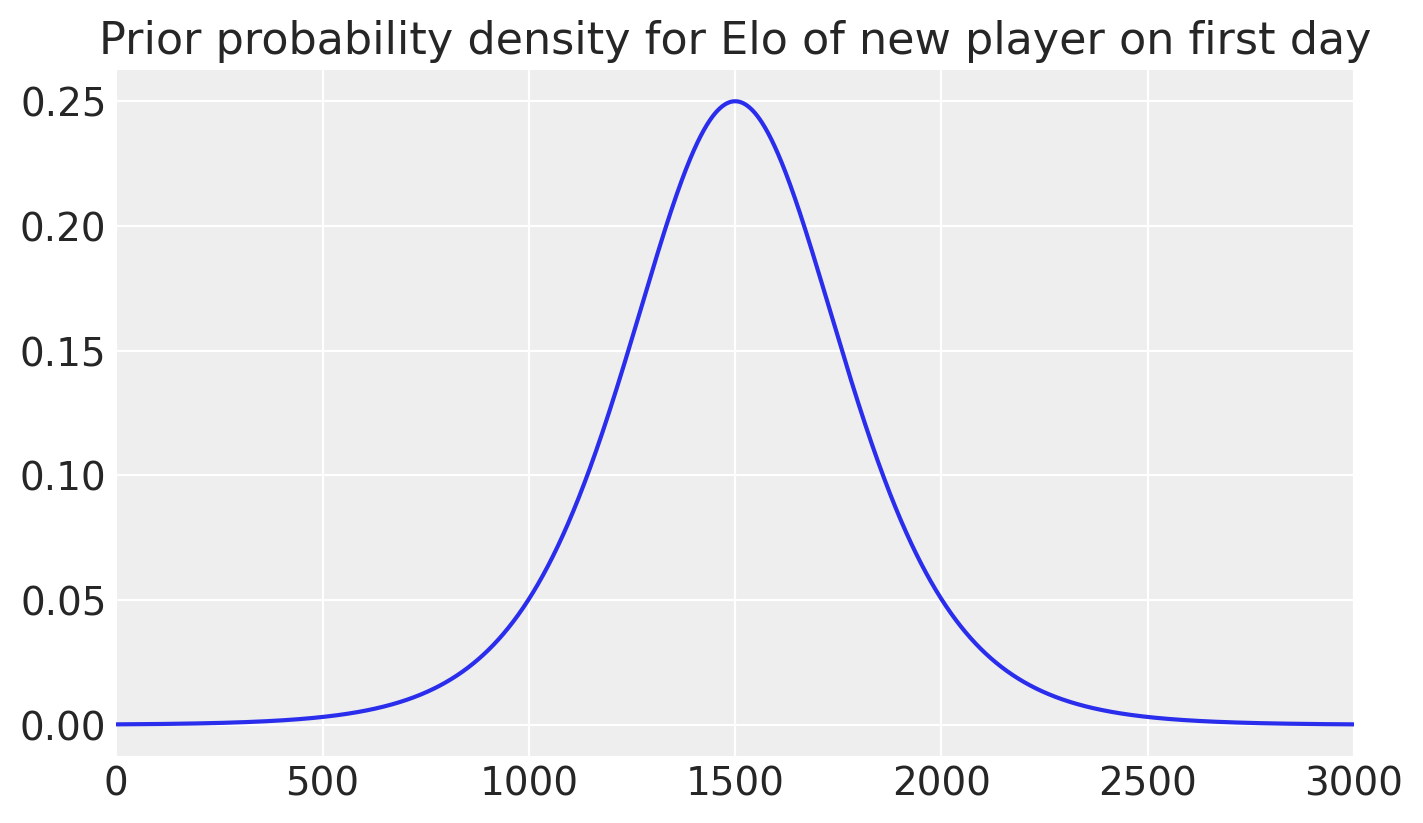
The prior used by WHR for the first-day rating of a new player is induced by assuming that the player had one fictional win and one fictional loss against a virtual 1500 Elo (0 natural rating) player. Since this is already a virtual Bayesian update, it raises the question of what the “prior of the prior” is, which I couldn’t find answered in the paper, but is presumably a flat improper prior. For implementation convenience, I used a broad normal distribution (sigma = 2000 Elo) instead of the flat prior, but the difference should be minimal.
Rating change between days
The prior used by Zero-K-WHR for the rating change of a player from one day to the next is a normal distribution with variance equal to: \[ \text{rating change of player P from day } d_1 \text{ to } d_2 \sim \text{Normal}(0, \sigma),\] \[ \sigma^2 = w \cdot 500 \text{ Elo}^2 + (d_2 - d_1) V \text{ Elo}^2\] where \[w := \text{weight of games P played on } d_2\] \[\text{where "weight" of a game = } \frac{1}{\text{number of players on P's team}}\] \[(\text{so 1 for 1v1, } \frac{1}{2} \text{for 2v2 etc.)}\] \[W := \text{total weight of all games P played up to } d_1\] \[V := \frac{200000}{W + 400}\]
The last part means that a new player starts out with a variance of \(\frac{200000}{400} = 500\) square Elo per day, but the variance per day slowly decreases to zero as they play more games. The additional variance per game weight remains constant though.
These constants are defined here.
Some example values for the standard deviation of the prior of rating change from day \(d_1\) to \(d_2\) for a player with W = 100 (that is 100 1v1s or 1000 10v10s played in total):
| σ [Elo] | σ [Elo] | σ [Elo] | |
|---|---|---|---|
| d2 - d1: Days since last game --> | 1 | 10 | 100 |
| w : Weight of games played on day d2 | |||
| 0.1 | 21.2 | 63.6 | 200.1 |
| 0.3 | 23.5 | 64.4 | 200.4 |
| 1.0 | 30.0 | 67.1 | 201.2 |
| 3.0 | 43.6 | 74.2 | 203.7 |
| 10.0 | 73.5 | 94.9 | 212.1 |
| 30.0 | 124.1 | 137.8 | 234.5 |
WHR is assuming that the skill of a player probably doesn’t change a huge amount in a short time and with few games played. It can be convinced of the opposite though, given strong enough evidence.
As an example for the importance of the prior for rating changes, consider a player who won all their games yesterday and lost all their games today. The maximum likelihood explanation would be that their rating was \(+\infty\) (or the maximum technically allowed rating) yesterday and \(-\infty\) today. This would make the likelihood of the observations 100%. But the prior says that player skill does generally not change that quickly, and in the end the assigned rating is a compromise between likelihood and prior probability. Their rating was higher yesterday than today, but not so extremely.
From a design perspective, these priors could be modified to achieve some desired goal (such as slower or faster rating changes) while staying within the same Bayesian framework.
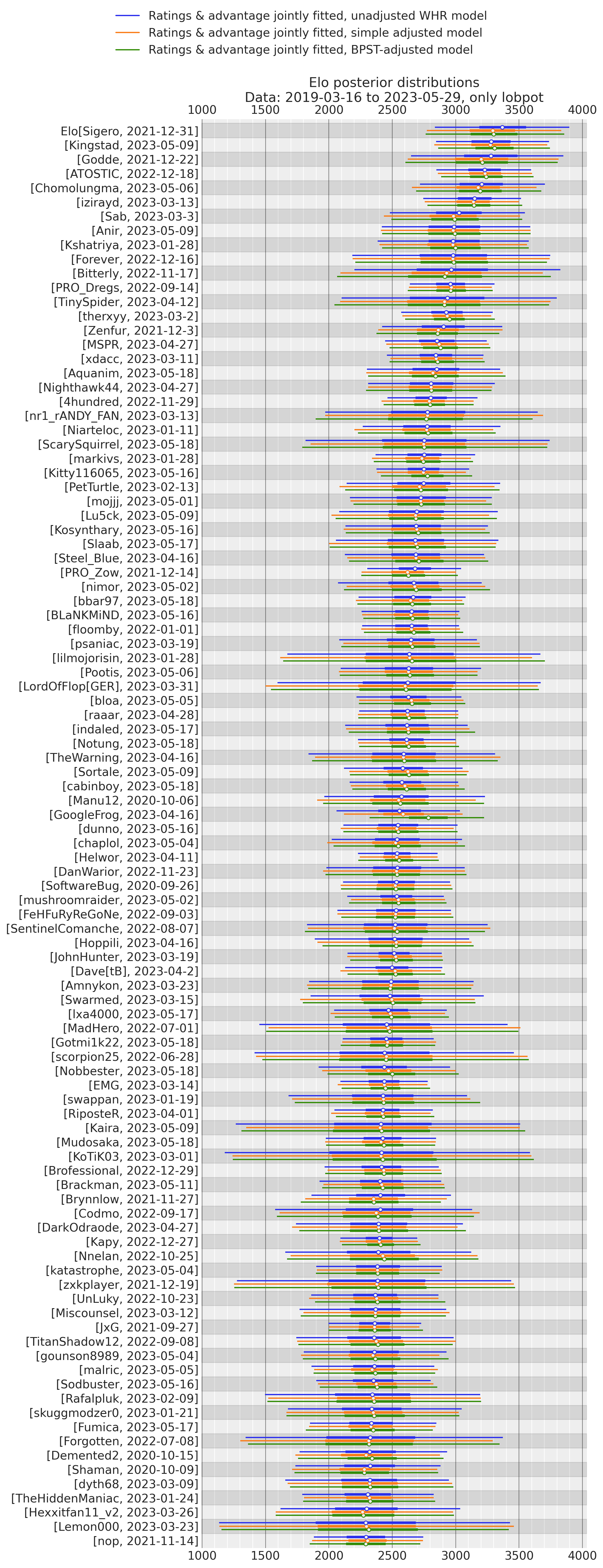
Top 100
As a sort of plausibility check, here are the Top 100 sorted by the posterior mean of rating in the unadjusted model (only last available day for each player). It’s unsurprising that there’s little change in Elo in the adjusted models, since frequent players should have no systematic tendency to be either on the smaller or the larger team, so the Elo gained/lost from the adjustment for being in the small/large team should cancel out.
Thin lines are 95% highest density intervals, thick lines are interquartile ranges.
Footnotes
For 8v9 and bigger, I assumed: \(P(\text{team 1 wins} | r) = \text{sigmoid}\left(r + \text{epad}_\text{8v9+} \cdot \frac{8}{\text{size of smaller team}}\right)\) Maybe the effect falloff for full pots should be bigger though (or I could just model each size up to 15v16 separately).↩︎
And that the
epads for different size games are somewhat correlated, whereas they are independent in the “objective” prior used here.↩︎The origin of the scale is also shifted; 0 natural rating corresponds to 1500 Elo (this is like degree C vs F for temperature), but this doesn’t matter when only computing the difference of two ratings. The only place where we aren’t just looking at differences is in the fictional win and loss on the first day vs. a 1500 Elo = 0 natural rating player. \[\text{A difference of r natural rating units} = \text{a difference of } \frac{400 r}{\ln(10)} \text{Elo}\] \[r \text{ natural rating (absolute) } = 1500 + \frac{400 r}{\ln(10)} \text{Elo (absolute)}\]↩︎